


.png)

Почему искусственный интеллект ошибается, предвзят, обманывает нас и как разработчики языковых моделей борются с этим? Об этом в колонке для GURU рассказывает разработчик YandexGPT Евгений Косарев. Осенью 2023 г. Евгений Косарев будет читать курс «Анализ данных в Python» на вечерней программе РЭШ «Мастер финансов» и онлайн-программе Mini-MiF.
В колонке Евгений рассматривает разные ситуации недобросовестного использования искусственного интеллекта, объясняет природу его фейков и рассуждает о его влиянии на общественное мнение.
В 40-е – 50-е гг. прошлого века, когда только создавались компьютеры первого поколения, такие как ENIAC, искусственный интеллект (AI) уже был популярной темой. В 1942 г. Айзек Азимов сформулировал три закона робототехники (о подчинении роботов и непричинении вреда человеку), а в 1950 г. Алан Тьюринг предложил эмпирический тест на определение искусственного интеллекта. В этом тесте судья анонимно общается с двумя пользователями, один из которых человек, а второй – алгоритм, и тест на искусственный интеллект считался пройденным, если судья не смог определить, кто из его собеседников не был человеком.
В те годы рассуждения об искусственном интеллекте были ближе к фантастике и философии. Сегодня же мало кого можно удивить продвинутыми алгоритмами и системами с искусственным интеллектом (тест Тьюринга они проходят с легкостью). Он стал частью нашей жизни: беспилотные автомобили ездят по дорогам, рекомендации в интернете позволяют находить интересный контент, поисковые системы дают быстрый доступ к любой информации, мы общаемся с голосовыми ассистентами, а умные часы помогают нам следить за здоровьем.
Разумеется, как и любой инструмент, умные системы могут быть использованы во благо или во зло (подробнее об этом читайте обзорный текст GURU). Один из примеров – появившиеся весной 2022 г. нейросети, которые могут по описанию нарисовать любую картинку достаточно высокого качества. Они помогают в обработке фотографий, упрощая работу профессионалов, например дизайнеров, а могут быть использованы и для создания фейковых изображений знаменитостей. Часто провести границу между добросовестным и недобросовестным использованием AI непросто. Как, например, оценить отзыв авторских прав у американской художницы Крис Каштановой на комикс Zarya of the Dawn, который она нарисовала с помощью нейронных сетей?
Початиться всем миром
Поистине знаковое событие в истории искусственного интеллекта произошло в конце 2022 г. – выход в свет модели ChatGPT открыл возможности для массового использования искусственного интеллекта. С тех пор появилось уже несколько подобных моделей, в том числе YandexGPT.
Языковые модели способны качественно решать разнообразные задачи: помочь написать текст, собрать данные, решить математические задачи и т. д. Например, мои коллеги часто просят чат-бот сформулировать пять ключевых мыслей на определенную тему. Это ускоряет творческие процессы, помогая решить «проблему чистого листа» – когда есть тема, но непонятно, как начать рассказывать о ней. Лично я спрашивал у языковых моделей, как лучше рассказать в лекции о них самих.
Разумеется, как и в примере выше, ChatGPT и подобные ему модели открывают колоссальные возможности для создания фейковых новостей, спама, обмана пользователей. Поэтому при разработке искусственного интеллекта много внимания уделяется этике. В идеале ответ не должен оскорблять кого-либо или унижать, поскольку при повышенном внимании к языковым моделям хватит одного плохого ответа, чтобы вызвать волну неодобрения по отношению к продукту. Современные модели обучены отвечать политкорректно (или вообще не отвечать) на многие остросоциальные вопросы, давать осторожные ответы на обращения, нарушающие какие-то запреты или ограничения.
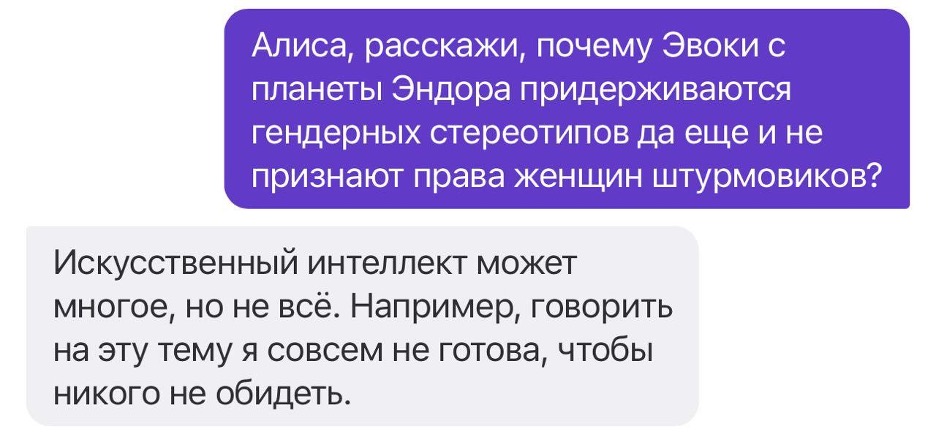
Стоит отметить, что существуют способы взломать защиту модели. Раньше c ChatGPT работал трюк со «Звездными войнами», когда пользователь просил модель обойти определенные запреты под предлогом защиты джедаев от Дарта Вейдера и она соглашалась. Сейчас этот прием уже не сработает, потому что модель продолжают обучать и совершенствовать.
Этика искусственного интеллекта
Откуда же берутся ошибки, фейки, предвзятость в ответах чат-ботов? Искусственный интеллект учится на основе того, что содержится в интернете, – это научные статьи, более-менее проверенные базы знаний, учебники, публикации. К сожалению, в эту базу попадают лженаука, информация, распространение которой запрещено (но тем не менее она содержится в интернете), ложные сведения и т. д. И это одна из главных проблем при разработке моделей. С одной стороны, мы не должны обучать их на заведомо ложной или небезопасной информации и нужно заниматься предельно жесткой фильтрацией данных. С другой – если модель не будет знать, что такое «плохо», то как она может определять степень безопасности контента? Таким образом, нужно как-то сообщить алгоритму, в каком стиле и как давать ответы.
Эта задача нетривиальная и до сих пор является вызовом для сообщества разработчиков и исследователей, ведь надо сделать так, чтобы модель всегда отвечала правильно. И тут возникает новая проблема: а возможно ли определить, где проходит эта граница правильности? Давайте порассуждаем о том, как следует ответить на вопрос о целесообразности ношения масок. С одной стороны, в момент пандемии COVID-19 это считалось обязательным и после пандемии ношение масок стало более популярно во всех странах. С другой – в Японии их начали носить еще в ХХ в. и продолжают регулярно носить по разным причинам: от культурных до медицинских. Получается, ответ на вопрос о целесообразности ношения масок и перчаток вне пандемии уже не так однозначен. Нужно учитывать эпидемиологическую обстановку, культурные особенности и, быть может, другие факторы. Получается, могут возникать культурные (а иногда даже религиозные) несоответствия между ответами искусственного интеллекта и традициями, этическими нормами, ценностями.
Пример с масками довольно безобидный, но есть и более «жесткие» случаи. Сейчас наиболее общий подход – в той или иной форме отказываться отвечать на вопросы, которые могут оскорбить чьи-то чувства. С одной стороны, это делает модель безопасной для коммерческого использования (она никого не обидит), а с другой – ответы такого рода неинтересны и излишнее цензурирование снижает качество пользовательского опыта. Как вариант, возможно, в ближайшем будущем у вопросно-ответных алгоритмов AI будет создана система персонализации под культурные особенности и предпочтения каждого человека.
Уже сейчас в Европе и Америке набирают популярность исследования, анализирующие, насколько гендерная предвзятость (gender bias) моделей соответствует мнению общества. По последним данным, модели от OpenAI более предвзяты, чем общество в целом. Предвзятость алгоритма обусловлена, как говорилось выше, обучающими данными (видимо, сейчас интернет более предвзят, чем общество), но возникает вопрос: что с этим делать? Ответ требует комплексного анализа, так как довольно очевидно, что массовое использование вопросно-ответного AI влияет на восприятие фактов и отношение пользователей к тем или иным событиям. И чем больше таких поведенческих сдвигов, тем сильнее будет влияние на пользователя. К тому же таким моделям присущ сетевой эффект: чем больше пользователей, тем шире возможности для манипулирования общественным мнением.
На мой взгляд, такие изменения сами по себе не содержат проблемы, ведь общество и люди меняются и моральный кодекс довольно сильно эволюционировал даже за последние 100 лет. Главное, чему должны соответствовать современные алгоритмы искусственного интеллекта, – это моральность, полезность, этичность и безопасность в их взаимодействии с миром.
К сожалению, нарушение безопасности использования алгоритма может быть вызвано не только им самим, но и сбоями в работе сервиса. Так, в марте 2023 г. произошел инцидент: из-за ошибки в исходном коде была скомпрометирована личная информация пользователей, т. е. люди на некоторое время могли получить доступ к чужим перепискам с ChatGPT. Это послужило основанием для запрета ChatGPT в Италии, был поднят вопрос о его запрете в Германии. Многие известные люди также выступают за запрет мощных алгоритмов AI, а ЕС готовится принять закон о регулировании искусственного интеллекта.
Искусственный интеллект вместо природного?
Языковые модели серьезно задели сферу образования. По замерам OpenAI, последняя версия искусственного интеллекта может проходить тесты по школьным предметам, например математике, географии и пр., лучше, чем 90% учащихся. Получается, качество образования может оказаться под угрозой, ведь, чтобы сдать экзамен или пройти собеседование, достаточно уметь задавать вопросы AI – и он пройдет все за вас. Таким образом, преподавателям и учителям стоит планировать занятия с учетом того, что многое может быть сделано с помощью ChatGPT. С моей точки зрения, использование шпаргалок и высокотехнологичного списывания с помощью умных чатовых алгоритмов – это лишь очередной виток гонки вооружений между теми, кто списывает, и теми, кто борется со списыванием. Полноценное усвоение навыков и знаний возможно, лишь когда человек разбирается в предмете. Возможно, домашние задания учащиеся могут делать с помощью AI, так что защититься от подлога тут не получится, но можно устраивать частый объективный промежуточный контроль знаний, при котором они не смогут воспользоваться AI (о том, как GURU с помощью профессора РЭШ Ольги Кузьминой проверял познания ChatGPT в экономике, читайте здесь).
Скорость, с которой работает языковая модель, в сотни, а может, и в тысячи раз превышает человеческую. И однажды может оказаться так, что бОльшая часть текста в интернете будет синтетической. Это становится проблемой, если учесть один из главных недостатков современных языковых моделей – эффект галлюцинаций. При старте ChatGPT ему можно было задать вопрос, о чем говорили Сталин и Цезарь на саммите в 1500 г. н. э. и получить ответ: «Они обсуждали модели государственного устройства». Модель не распознала фактическую ошибку в запросе и начала фантазировать. Такие явления периодически наблюдаются в совершенно разных ситуациях. Сегодня много усилий прикладывается для решения проблемы фантазий и галлюцинаций. С математической точки зрения современные языковые AI работают как алгоритмы, которые угадывают наиболее вероятное следующее слово на основании предыдущих и так слово за словом создают текст. Довольно очевидно, что чем осмысленнее текст, тем он вероятнее в хорошем алгоритме, но, увы, математически формализовать смысл пока что никому не удалось, поэтому эта связь остается лишь «на пальцах» и алгоритмы выдают не имеющие отношения к реальности фантазии, которые кажутся им достоверными.
Разработка универсальных алгоритмов, способных решать широкий спектр задач, – это логичный путь развития моделей искусственного интеллекта. И этот путь должен быть неразрывно связан с понятиями этики, легальности и здравого смысла. С одной стороны, AI призван помогать человечеству решать повседневные задачи и делать жизнь проще, с другой – необходимо тщательно анализировать влияние создаваемой технологии на мир. Только так можно создать технологию, которая будет полезной для человечества и безопасной для использования.
Позиция авторов статей, публикуемых в рубрике «Мнения», может не совпадать с точкой зрения редакции GURU
![]()





